Forward Forward Neural Networks
December 27, 2022
At the NeurIPS conference in 2022, Geoffrey Hinton proposed a new architecture for training neural networks using an algorithm called Forward-Forward. Forward-Forward is a biologically plausible alternative to the conventional backpropagation approach to training neural networks, and here I demonstrate an implementation fo the basic algorithm, applied to solve the MNIST handwritten digit classification problem.

Traditional feedforward neural networks were first discovered in the 1940s as a combination of single perceptrons, and they achieved greater success as increases in computational power enabled ever larger networks to be trained. Training feedforward neural networks typically relies on backpropagation, where for each layer of the network, the weights are updated according to a gradient that is computed with respect to the layer’s input.
A single layer of a feedforward neural network computes the product between its inputs and its weights to produce an intermediate result, $h=w^Tx$. This intermediate result is passed through a nonlinear function $f$, such as a sigmoid function, so that a layer’s output is $a=f(h)$. To train a feedforward neural network, we first compute the forward pass through all the layers of the input data, by computing both $h$ and $a$, and storing $\frac{\partial h}{\partial x}$. Then, a loss function tells us how far off our network’s prediction was from the input. To update the weights of layer $i$ and actually “learn”, we perform a backwards pass by moving backwards from the last layer to the first layer, computing the gradient of layer $i$’s prediction with respect to layer $i-1$’s activation, which was that layer’s input. This means we compute the derivative of the layer’s output $a$, with respect to the layer’s input $x$, as $\frac{\partial a}{\partial x}=\frac{\partial a}{\partial h}\cdot\frac{\partial h}{\partial x}$. This is possible because on the forward pass, we computed and stored the value of $\frac{\partial h}{\partial x}$. This approach, called backprop, is used in almost all modern neural networks.
Neural networks originated from mimicking the structure of the human brain, where neurons transmit information to each other via electrical impulses akin to activations. However, backpropagation doesn’t seem like an elegant solution that nature would come up with for learning — backprop relies on storing information from the forward pass to be used in the backwards pass, and requires propagating error derivatives backwards during learning. There isn’t much biological evidence for neurons storing information from the forward pass, nor for neurons passing information backwards during learning. Could we train neural networks in a different way?
Positive and Negative Data
Traditional neural networks are trained by providing the network with an input x and a desired output y. The network is given x as input, and at the end, the network’s prediction is compared to the ground truth value of y using a loss function. This loss function tells the network how far off it was from predicting the ground truth value, and taking the derivative of this function with respect to x provides a way to update the network’s weights according to gradient descent.
Forward-forward networks have to rely on a different approach since they want to avoid computing a loss function for the entire network. The core idea of the forward-forward network is to train each layer individually so that each layer responds most “positively” to positive data and most “negatively” to negative data. This means we want our network’s layers to produce a high activation when it sees positive data, and a low activation about negative data. Utilizing positive and negative data may not seem intuitive at first, but by demonstrating to the network good and bad inputs, our network will be able to update its weights and learn without computing global derivatives. Because we can’t tell our network after the end of a forward pass how close it was to the ground truth value, we must incorporate both $x$ and $y$ into good and bad data. We can say good data is data where the label $y$ matches the input $x$, and bad data is data where the label $y$ does not match the input $x$. By providing both good and bad data with the same $x$’s, the network can compute derivatives on the basis of recognizing correct labelings of $y$ from incorrect labelings of $y$.
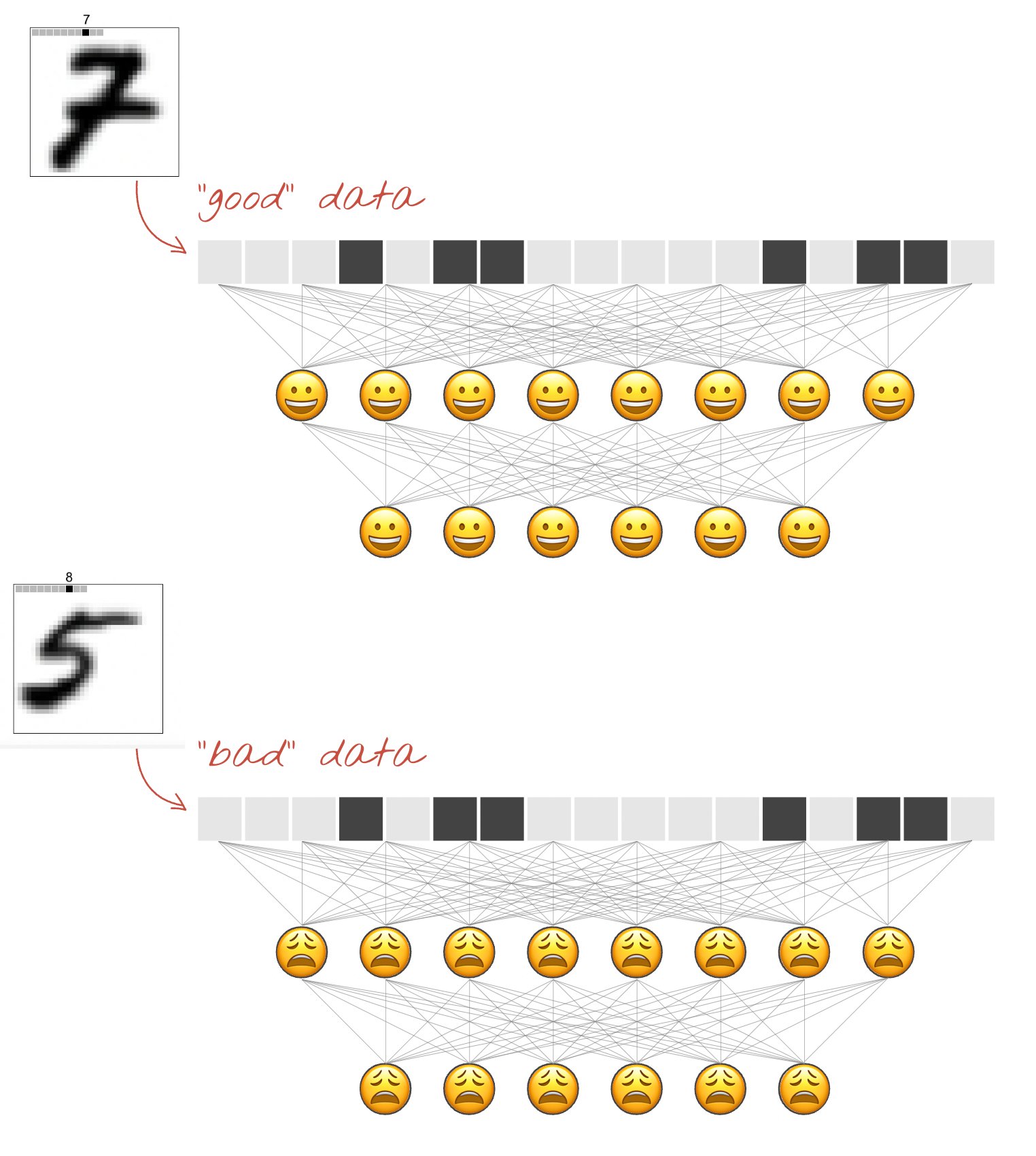
(Source)
Forward-Forward doesn’t require storing information during the forward pass, nor propagating gradients from one layer to another. Moreover, it is far more biologically plausible than backpropagation since it doesn’t require interrupting to propagate error derivatives.
Here, I’ll walk you through a simple implementation of the forward-forward algorithm to train a neural network to classify MNIST handwritten digits. See all the source code here, where you can also open it in Google Colab.
Utilities
Since the forward-forward network expects inputs to contain both the data $x$ as well as the label $y$ together, we concatenate the data and label together. Note that there are 10 possible output classes.
def combine_x_y(x, y):
x_ = x.clone()
label_onehot = torch.nn.functional.one_hot(y, 10) * x.max()
return torch.hstack([x, label_onehot])
A single layer
Let’s define a single layer first. We’ll inherit from a linear layer, since the output is computed as the activation function applied to the intermediate multiplication of input and weights, $a=f(h)$ where $h=w^Tx$.
class Layer(torch.nn.Linear):
def __init__(self, in_features, out_features, bias=True, device=None, dtype=None):
super().__init__(in_features, out_features, bias, device, dtype)
# define the components we will use
self.activation = torch.nn.ReLU()
self.optimizer = torch.optim.Adam(self.parameters(), lr=0.03)
# define hyperparameters
self.num_epochs = 1000
# keep track of losses during training
self.losses = []
Here we define the forward pass through this layer. This is the same as how a linear layer does it, taking the matrix multiplication of $x^T$ and the weights and adding the bias term. The difference is that here we first normalize the input to the layer, so we first take only the unit vector of the input. Remember that because the previous layer will output a vector of differing magnitude depending on how “excited” it is about its input, taking the norm of the vector guarantees that only the direction of the output from the previous layer is used to determine how excited this layer is about, the input.
def forward(self, x):
x_normalized = x / (x.norm(2, 1, keepdim=True) + 1e-8)
# w^T + b
return self.activation(
torch.mm(x_normalized, self.weight.T) + self.bias.unsqueeze(0)
)
Each layer of the forward-forward network can train itself, because it does not rely on gradients from other layers in the network. All it needs is a source of positive and negative data. There are several ways we could define a “positive” response versus a “negative” response, but the simplest approach could be just the L2 norm (magnitude) of the vector outputted by the layer. The first layer of the network receives data as the concatenation of X and Y (data and label), while subsequent layers receive the output of the previous layer’s forward pass on the positive and negative data for X and Y, respectively.
def train(self, x_positive, x_negative):
self.losses = []
for i in range(self.num_epochs):
goodness_positive = self.forward(x_positive).pow(2).mean(1)
goodness_negative = self.forward(x_negative).pow(2).mean(1)
We define our loss function so that if we were to minimize it, we would end up having to maximize the goodness of x_positive, and minimize the goodness of x_negative. This cost function provides the surface for which we find the gradient to minimize.
loss = torch.log(1 + torch.exp(torch.cat([-goodness_positive + self.threshold,
goodness_negative - self.threshold]))).mean()
Notice that even though we compute a gradient, this gradient is only local — it is computed solely from information in this layer, and is not passed to another layer, unlike in backprop.
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.losses.append(loss.item())
Finally, the goodnesses of the positive data and the negative data computed in this layer’s forward pass is needed to train the next layer.
return self.forward(x_positive).detach(), self.forward(x_negative).detach()
A Network
Now that we’ve defined a single layer, let’s combine a few of them into a multi-layer network. We’ll build our network by adding layers, each with the input dimensions of the previous layer, and the output dimensions of the next layer. The first dimension is the dimension of our input data.
class FFNN(torch.nn.Module):
def __init__(self, dims):
super().__init__()
self.layers: List[Layer] = []
for d in range(len(dims) - 1):
self.layers.append(Layer(dims[d], dims[d+1]).cuda())
To train our network, all we do is ask each layer to train itself. Notice how this only requires one pass through the layers, and the only data shared is the forward pass result of each layer.
def train(self, x_positive, x_negative):
h_positive, h_negative = x_positive, x_negative
for i, layer in enumerate(self.layers):
print('Training layer', i)
h_positive, h_negative = layer.train(h_positive, h_negative)
To predict which class an image $x$ belongs to, we can present our network with the input $x$ concatenated with each possible class, and see which label appended to the image is the network most excited about by computing the forward pass. Specifically, we compare the total activation across all layers of the entire network.
def predict(self, x):
goodness_per_label = []
for label in range(10):
First, we generate an array of just that label, and append it to all $x$.
label_arr = [label] * x.shape[0]
input = combine_x_y(x, torch.tensor(label_arr).cuda())
Then, we pass this input through the network and record the sum activation across all the layers.
goodnesses_per_layer = self._forward_pass(input)
goodness_per_label.append(sum(goodnesses_per_layer).unsqueeze(1))
The class that the network predicts is the class of data that achieves the highest total activation. With $x$ remaining constant, the only differences in the activations comes from the label appended to $x$.
goodness_per_label = torch.cat(goodness_per_label, 1)
return goodness_per_label.argmax(1)
To compute the forward pass, we record the magnitude of the activations of each of the layers, passing each layer’s activation to the subsequent layer.
def _forward_pass(self, input):
h = input
goodnesses = []
for layer in self.layers:
""" Goodness is computed as the magnitude of the activations of this layer """
activation = layer(h)
activation_magnitude = activation.pow(2).mean(1)
goodnesses.append(activation_magnitude)
""" Use the activation of this layer as the input to the next layer """
h = activation
return goodnesses
Training
def MNIST_loaders(train_batch_size=50000, test_batch_size=10000):
transform = Compose([
ToTensor(),
Normalize((0.1307,), (0.3081,)),
Lambda(lambda x: torch.flatten(x))])
train_loader = DataLoader(
MNIST('./data/', train=True, download=True, transform=transform),
batch_size=train_batch_size, shuffle=True)
test_loader = DataLoader(
MNIST('./data/', train=False, download=True, transform=transform),
batch_size=test_batch_size, shuffle=False)
return train_loader, test_loader
torch.manual_seed(42)
train_loader, test_loader = MNIST_loaders()
To create our positive data, we combine images and their correct labels.
x, y = next(iter(train_loader))
x, y = x.cuda(), y.cuda()
x_positive = combine_x_y(x, y)
To create negative data, we can combine our images with random labels.
rnd = torch.randperm(y.size(0))
x_negative = combine_x_y(x, y[rnd])
Let’s make a network with 2 layers of 500 neurons each, and train it.
input_dimension = x_positive[0].size(0)
network = FFNN([input_dimension, 500, 500])
network.train(x_positive, x_negative)
print('Training error:', 1.0 - network.predict(x).eq(y).float().mean().item())
x_test, y_test = next(iter(test_loader))
x_test, y_test = x_test.cuda(), y_test.cuda()
print('Test error:', 1.0 - network.predict(x_test).eq(y_test).float().mean().item())
After training with 1000 epochs on each layer, this network receives a training error of approximately 0.0715 on the training dataset, and 0.0709 on the test dataset. Plotting losses shows loss for both layers decreases nicely over training!

